1 Flicker的解决方案
MySQL中id自增的特性,可以借此来生成全局的序列号,Flicker在解决全局ID生成方案里就采用了MySQL自增长ID的机制(auto_increment + replace into + MyISAM)。一个生成64位ID方案具体就是这样的: 先创建单独的数据库,然后创建一个表:
CREATE TABLE borrow_order (
id bigint(20) unsigned NOT NULL auto_increment,
stub char(1) NOT NULL default '',
PRIMARY KEY (id),
UNIQUE KEY stub (stub)
) ENGINE=MyISAM
当我们插入记录后,执行SELECT * from borrow_order ,查询结果就是这样的:
+-------------------+------+
| id | stub |
+-------------------+------+
| 1 | 192.168.100.102 |
+-------------------+------+
在我们的应用端需要做下面这两个操作,在一个事务会话里提交:
REPLACE INTO borrow_order (stub) VALUES ('192.168.100.102');
SELECT LAST_INSERT_ID();
上述操作,通过 replace into 操作,首先尝试插入数据到表中,如果发现表中已经有此行数据则先删除此行数据,然后插入新的数据。 如果没有此行数据的话,直接插入新数据。注意:插入的行字段需要有主键索引或者唯一索引,否则会出错
通过上述方式,就可以拿到不重复且自增的ID了。 到上面为止,我们只是在单台数据库上生成ID,从高可用角度考虑,接下来就要解决单点故障问题:Flicker启用了两台数据库服务器来生成ID,通过区分auto_increment的起始值和步长来生成奇偶数的ID。
DBServer1:
auto-increment-increment = 2
auto-increment-offset = 1
DBServer2:
auto-increment-increment = 2
auto-increment-offset = 2
最后,在客户端只需要通过轮询方式取ID就可以了。
优点:充分借助数据库的自增ID机制,提供高可靠性,生成的ID有序。 缺点:占用两个独立的MySQL实例,有些浪费资源,成本较高 数据库中记录过多,每次生成id都需要请求数据库
2 优化方案
采用批量生成的方式,内存缓存号段,降低数据库的写压力,提升整体性能
2.1 方案1 mysql双主架构
采用双主架构的方式来显示高可用,数据库只值存在已备用号段的最大值。 我们新建一张表
CREATE TABLE `id_generator` (
`id` int(10) NOT NULL,
`current_max_id` bigint(20) NOT NULL COMMENT '当前最大id',
`increment_step` int(10) NOT NULL COMMENT '步幅长度',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
如此我们可以通过 getIdService服务 来对单实例数据库批量获取id,具体步骤如下:
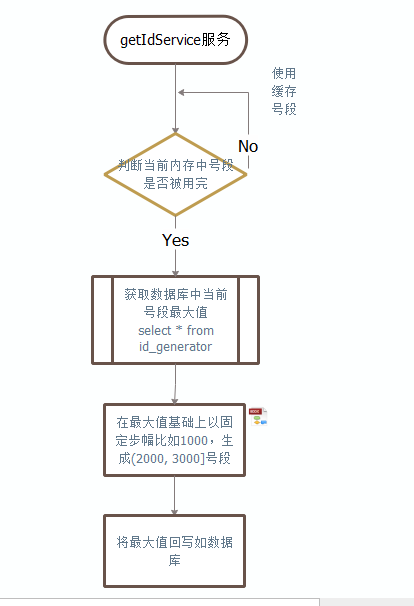
优缺点 >优点 数据库只保存一条记录 性能极大增强
缺点: 如getIdService重启,内存中未使用的ID号段未分配,导致ID空洞 服务没有做HA,无法保证高可用
问题解决方案: 数据库使用双主架构保证高可用,服务通过多个getIdService服务去获取Id,减少ID空洞的数量
上述方案还是存在问题,当多个服务去访问数据库,或者同一服务同时多个线程去访问就会产生竞态条件,产生并发安全问题。 在当前读多写少的场景下,我们可以使用数据库CAS乐观锁去解决并发问题来保证原子性。
假设 同时有两个服务获取到current_max_id的最大值都是3000,然后生成号段后,
回写数据库update id_generator set current_max_id=4000; 此时就会产生的id就会重复,
我们通过CAS方式改写为:update id_generator set current_max_id=4000 where max_id=3000;
来保证生成的id全局唯一
该方案的好处是:
水平扩展达到分布式ID生成服务性能 使用CAS简洁的保证不会生成重复的ID
缺点: 由于有多个service,生成的ID 不是绝对递增的,而是趋势递增的
2.2 方案2 多实例
基于Flicker方案
REPLACE INTO borrow_order (stub) VALUES ('192.168.1.1');
SELECT LAST_INSERT_ID();
当多个服务器的时候,这个表是这样的:
id stub 5 192.168.1.1 2 192.168.1.2 3 192.168.1.3 4 192.168.1.4
每台服务器设置好增幅只更新自己的那条记录,保证了单线程操作单行记录。这时候每个机器拿到的分别是5,2,3,4这4个id。这方案直接通过服务器隔离,解决原子性获得id的问题。
2.3 服务层原子性操作CAS
我们可以AtomicLong来实现ID自增,流程图如下:
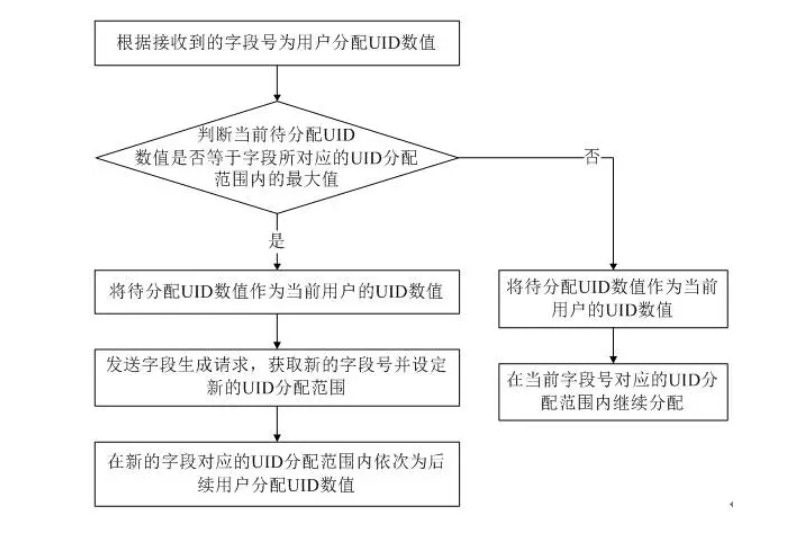
伪代码实现
private static AtomicLong atomicLong;
private static Long currentMaxId;
public synchronized static void deployIdService(String[] args) {
//判断是否为空调用id生成服务
getIdService();
//判断内存中的号段是否使用完
if (atomicLong.get() < currentMaxId) {
//获取id
long id = atomicLong.getAndIncrement();
}else {
//使用重新分配
atomicLong.set(200);
currentMaxId = 300L;
}
}
这里有个小问题,就是在服务器重启后,因为号码缓存在内存,会浪费掉一部分用户ID没有发出去,所以在可能频繁发布的应用中,尽量减小号段放大的步长n,能够减少浪费。 如果再追求极致,可以监听spring或者servlet上下文的销毁事件,把当前即将发出去的用户ID保存起来,下次启动时候加载进入内存。
[评论][COMMENTS]